L’analyse de logs, ce qu’il faut savoir et exemples d’utilisation

- Le Maillage interne ou Comment faire du Multi PageRank Sculpting
- Le glossaire du crawl en SEO
- L’analyse de logs, ce qu’il faut savoir et exemples d’utilisation
- [video] Comment créer un tableau de bord SEO via les logs ?
Je parle souvent de l’intérêt de l’analyse de logs en SEO et j’avais pas pris le temps encore d’en faire un article tant le sujet peut être long et complexe à résumer dans un seul article. Je vais ici tenter d’expliquer les informations qu’on peut en extraire en analysant ces données et surtout en les croisant avec d’autres. Comme à mon habitude, je vais essayer de vulgariser au maximum mais si certains termes techniques vous échappent, je vous invite à lire les définitions autour du crawl en SEO.
C’est quoi des logs ?
Les logs sont des fichiers hébergés sur le serveur web du site à analyser qui enregistrent régulièrement le passage de Googlebot sur le site et n’importe quel autre visiteur. Googlebot, le robot de Google chargé d’explorer les pages du web, étant un visiteur comme les autres ou presque. Les logs permettent de récupérer le passage de GoogleBot sur le site, celui des visiteurs et notamment des visiteurs qui viennent du moteur de recherche, et pleins d’informations: date de la visite, l’url visitée, l’url source (referrer), le code réponse de la page (code 404, code 200, ..), son poids , etc..
A quoi servent les logs en SEO?
Les logs en SEO servent à comprendre comment Google perçoit le site en permettant, de base, de savoir:
- Quelles pages sont vues (crawlées) par Google
- Quelles pages ne sont pas crawlées par Googlebot ?
- A quelle fréquence il explore le site et comment ça influe sur les visites
- Et beaucoup d’autres choses qu’on verra par la suite
Cela permet surtout de voir des choses qu’il est impossible de voir autrement, surtout lorsqu’il s’agit de sites à grosse volumétrie. Et même à partir de sites avec plusieurs milliers de pages, on identifie déjà des éléments essentiels à corriger et qu’on aurait pas découvert sans analyse de logs. J’en parlerai plus en détails lorsque je parlerai de budget de crawl mais il faut bien comprendre que Google ne crawle jamais l’intégralité d’un site et qu’il y a souvent une grosse différence entre ce que Google connait et les pages qui sont en ligne.
Analyser les logs revient à analyser la base du référencement, c’est à dire l’exploration des pages par Googlebot. Car avant d’analyser les contenus du site et leur pertinence, il faut déjà qu’il puisse y accéder. Et ce n’est pas tout, de quelle manière il y accède, quelle temps il y passe, a quelle fréquence, toutes ces questions auxquelles je vais tenter de répondre.
Les logs servent aussi à quantifier, à donner des indicateurs chiffrés, à donner des preuves mathématiques sur le bien fondé des actions à mener sur le site. C’est plus facile de dire au client qu’il faut alléger son menu de navigation si on arrive à lui prouver par A + B que c’est néfaste au bon référencement du site. Ils permettent aussi de prioriser les différentes optimisations.
Quelles données peut on extraire grâce aux logs ?
Ce sera pas exhaustif mais en voici quelques unes:
- Taux de crawl: Ratio entre les pages vues par Google et les pages dans la structure
- Taux de pages actives: Ratio entre le spages du site et celles qui font au moins une visite
- L’age des pages actives: Est ce que les pages qui font des visites ont été crawlées il y a longtemps par Google ou récemment ?
- La fenêtre de crawl: le délai nécessaire entre 2 passages de Googlebot pour qu’une page fasse des visites.
- L’efficacité crawl / visites: le ratio entre le crawl de Google et les visites, plus c’est élevé plus son crawl est efficace. Un paragraphe y est consacré.
- Répartition du crawl et des visites par types de pages
- Répartition des codes réponses par types de pages (code 200: réponse normal / code 404: erreur / ..)
Le crawl dans tous ses états
Pour bien comprendre la suite, il y a une distinction à bien faire lorsqu’on parle de crawl. Le crawl est l’action d’un robot qui explore un site afin de l’indexer ou d’en extraire des données. Pour ce qui nous interesse, il y a 2 types de crawl à considérer:
- Le crawl de Googlebot, le robot de Google, celui qu’on va extraire grâce aux logs
- Le crawl d’un outil SEO de crawl, qui va suivre toutes les pages liées sur le site
l’outil SEO ou crawler, explore toutes les pages accessibles par au moins un lien dans le site, tandis que Googlebot crawle les pages qu’il connait grâce aux liens sur le site également (pas de manière exhaustive en revanche comme le crawler) mais aussi depuis n’importe quel autre source (autres sites faisant des liens vers le votre), depuis des pages qu’il a connu et qui ne sont plus accessibles sur le site, ou encore qu’il connait grâce au comportement utilisateur. C’est une différence majeure et c’est l’analyse combinée de ces 2 types de crawl qui vont nous permettre d’optimiser le référencement naturel du site.
Méthodologie
Il y a beaucoup d’outils SEO d’analyse de logs à présent qui aide à les extraire et qui montre certains indicateurs grâce à des modèles prédéfinis. Mais là ou ça devient vraiment intéressant, c’est lorsqu’on les combine avec des données de crawl, des données analytics ou d’autres, et surtout lorsqu’on crée ses propres analyses. L’interprétation des données issues de ce type d’outils n’est pas accessible au prophane et souvent le manque de souplesse des données fournies les rendent peu aptes à prendre des décisions. Cependant, ils permettent indéniablement de gagner du temps.
C’est pour ça que j’utilise aussi mes propres outils pour gagner en agilité et calculer certains indicateurs qui n’existent pas toujours dans ces outils, on y reviendra.Une bonne maîtrise d’excel est aussi indispensable pour faire des tableaux croisés dynamiques ou encore utiliser des macros. La connaissance de linux et de ses commandes (grep, awk,…) est aussi un gros plus pour manipuler les fichiers de logs.
Voici une commande ultra basique et bien pratique pour extraire les lignes qui contiennent Google dans les logs.
grep google *.log > google-logs.txt
Cette commande permet de travailler sur des fichiers plus légers et donc plus faciles à traiter. Cela permet aussi à l’administrateur système ou à la personne en charge, d’envoyer des logs allégés au consultant SEO, pas besoin d’avoir tout le reste car ça peut vite parler en plusieurs gigas pour de gros sites. Et des logs compressés (.gz), c’est bien aussi d’y penser , ça divise par 10 leur poids. Dans ce cas la commande devient:
zgrep google *.gz > google-logs.txt
La segmentation: indispensable pour une bonne analyse !

Exemple de catégorisation structurelle
La segmentation ou la catégorisation d’un site consiste à séparer le site par groupe de pages. Pour plus de détails, vous trouverez un exemple de catégorisation dans l’article sur l’audit technique . Ce qui est important de savoir lorsqu’on améliore le référencement d’un site, c’est qu’on optimise pas toutes les pages de manière uniforme. Bien sur, il faut faire en sorte que toutes les pages stratégiques soient optimisées avec un contenu pertinent, une sémantique optimale mais toutes les pages n’ont pas le même potentiel de trafic et les mêmes objectifs SEO.
On a:
- Des pages qui sont destinées à se positionner sur de la longue traîne comme des pages produits ou des articles éditoriaux
- Des pages de navigation qui sont destinées à se positionner sur de la top ou moyenne traîne et qui ont aussi un objectif de faire explorer les produits
- Des paginations qui n’ont pas d’objectif de positionnement, mais un léger objectif d’exploration de pages profondes qu’il faut toutefois limiter car elles sont peu efficaces en général
- Des pages sans réel intérêt pour le référencement et vers lesquelles il faut limiter le temps passé par Google (on reviendra sur le crawl budget)
- Des pages avec des thématiques différentes qu’on veut pousser différemment car certaines sont plus génératrices de conversions
En ce qui concerne l’optimisation des liens internes notamment, l’idée est de créer un déséquilibre entre ces différents groupes de pages en liant davantage certaines catégories de page. Le pagerank interne envoyé aux pages via les liens a bien sur une incidence sur le volume et la fréquence de crawl de Googlebot sur ces pages.
La nécessité de bien séparer un site par groupe de pages est d’ailleurs une des raisons qui font que les statistiques d’exploration de search console, qui montrent le nombre de pages explorées par Googlebot et par jour, ont un intérêt très limité car on ne sait pas quelles types de pages sont explorées.
Sur search console, dans certains cas, on peut voir le nombre de pages explorées qui augmentent brutalement mais ce n’est pas forcément une bonne nouvelle. Une fois, un client m’a appelé en me disant: « Super, mes statistiques d’exploration sont en hausse »… là je lui ai dit, Holà, du calme, c’est pas forcément une bonne nouvelle », et une analyse de ses fichiers de logs a révélé qu’il s’agissait en fait d’un gros effet de bord qui a conduit Google à crawler des pages dupliquées.
Ce gendre de cas montre l’intérêt de faire du monitoring de logs afin d’être alerté rapidement sur ce type d’erreurs. On a par la suite mis en place du monitoring par catégories de page et aussi remis à plat les process d’intégrations sur le site car le client avait mis en production un changement sans m’alerter au préalable et qui m’aurait permis de prévenir l’erreur.
Tout ça pour dire qu’une bonne segmentation, c’est surement l’étape la plus importante pour réaliser une bonne analyse de logs. Et cela nécessite de connaitre au moins les urls connues par Google via les logs et les urls connues par la structure via in crawler.
Pages orphelines: Urls connues uniquement de Google

Les pages orphelines (ou nomatch dans le jargon) sont des pages connues uniquement de Google mais non accessibles en naviguant sur le site, elles sont hors de la structure du site. On peut retrouver plusieurs cas:
- Des pages issues d’une ancienne version d’un site, non redirigées et que Google continue de crawler.
- Des pages produits arrivées à expiration qui sont logiquement retirées de la structure du site mais que Googlebot continue d’explorer.
- Un sitemap XML qui génèrent des urls inexistantes dans la structure.
Avant de voir les problèmes qu’elles engendrent, il faut comprendre que les pages orphelines sont très peu efficaces pour générer des visites. A partir du moment où des pages ne sont plus accessible par la structure de liens du site, leur potentiel de trafic va baisser progressivement. J’ai pu le vérifier à de nombreuses reprises à travers des analyses de logs sur différents sites, et c’est une certitude. C’est d’ailleurs la raison principale qui fait qu’un sitemap XML a très peu d’intérêt dans la plupart des cas.
Les pages orphelines ne sont plus liées sur le site, elles ne reçoivent donc plus de pagerank interne, plus de signaux sémantiques à travers les ancres de liens, elles perdent donc leur pouvoir à générer des visites. Mais attention, ça ne veux pas dire qu’elles ne font pas de visites et qu’elles ne peuvent pas en faire, elles sont moins efficaces que des pages correctement liées dans la structure. Il ne s’agit donc pas de s’en débarrasser n’importe comment à coup de disallow ou de noindex par exemple, surtout dans le cas d’une migration.
Les principaux problèmes avec le crawl de Googlebot sur les pages orphelines c’est qu’elles peuvent entrer en concurrence avec le crawl des urls dans la structure, et c’est un problème pour le budget de crawl qu’on va voir plus en détails dans le prochain paragraphe. Ceci dit, c’est assez simple à comprendre, si Google gaspille du temps à crawler des pages non efficaces au détriment des pages efficaces dans la structure, on a un souci…
Nettoyer le site pour libérer du budget de Crawl
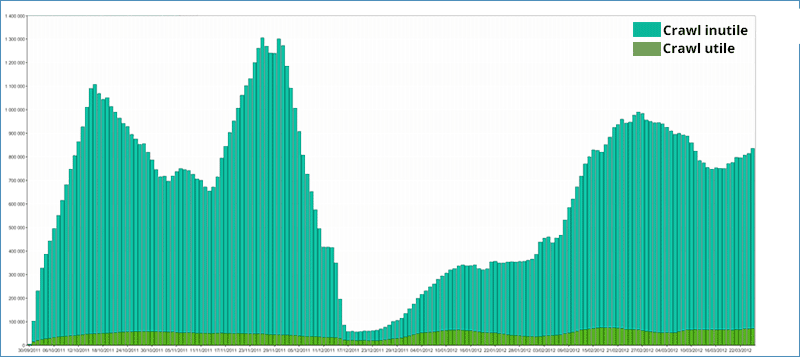
La première étape lorsque je réalise un audit SEO avancé, une fois l’analyse réalisée, c’est de nettoyer le site, c’est à dire de supprimer ou de limiter le crawl de Google vers des pages sans objectif de positionnement que j’appelle de manière un peu expeditive: « des pages inutiles ». A noter qu’ elles ne le sont pas forcément pour l’utilisateur, un formulaire de contact par exemple, même si on va pas chercher à le positionner, est utile pour l’utilisateur et pour le propriétaire du site.
Le budget de crawl (ou crawl budget) c’est l’énergie ou le temps accordé par Google pour crawler un site. On parle aussi de quota de crawl et qui dépend de la popularité du site et de la « somme » de ses pageranks. Imaginez bien que Google n’a pas une énergie infinie à consacrer à l’exploration de votre site, les robots de Google explorent des centaines de milliards de pages Web dans le monde comme il le confirme sur son site.
C’est à cause de ce budget de crawl qu’il y a toujours une différence et souvent de grosses différences entres les pages qu’il connait et les pages en ligne. Ce processus de nettoyage consiste à libérer du crawl globalement vers le site en supprimant celui vers les pages inutiles. L’objectif est purement mécanique: plus de crawl, plus de pages indexées, plus de pages qui font des visites. Les pages inutiles à nettoyer peuvent être:
- des pages dupliquées, qui, au delà de gaspiller du crawl, pénalisent la pertinence du site.
- Des pages d’erreurs (404,403,..) des redirections (on verra un cas d’usage)
- des soft 404, des pages qui ressemblent à des erreurs mais qui répondent comme une page normal
- Des pages orphelines qui ne font pas de visites et d’autres pages qu’on ne veux pas référencer.
Pour augmenter le budget de crawl, on peut aussi améliorer le temps de chargement des pages , augmenter le volume de pages du site car cela a une incidence sur le pagerank global du site, optimiser son netlinking et plus globalement la notoriété su site.
Orienter le crawl de Google
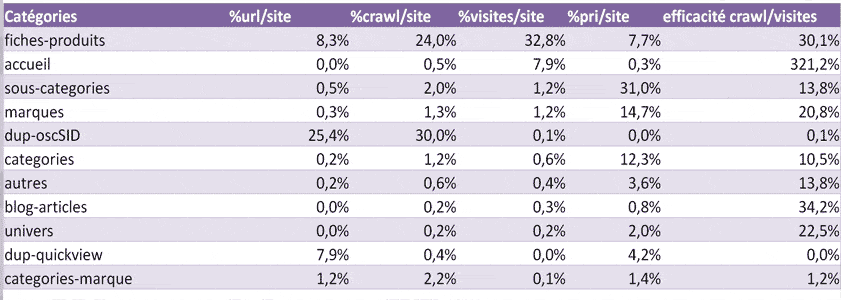
L’analyse des logs permet de libérer du crawl grâce au nettoyage, ce qui permet souvent d’avoir, la plupart du temps, un impact positif sur la visibilité du site . Mais pour que ce soit encore plus efficace, encore faut il orienter ce crawl vers les bonnes pages. C’est d’ailleurs un des objectifs principaux du pagerank sculpting comme j’en parle dans cet article. Seul les logs permettent de voir ce que Google voit, dans quelles proportions, à quelle fréquence, pour quelle efficacité sur le trafic, et de voir aussi ce qu’il ne voit pas.
Pour orienter le crawl de Google, il est essentiel de connaitre la distribution du crawl par groupe de pages. Dans le tableau ci-dessus, on voit par exemple que 30% du crawl de Google s’effectue sur des pages dupliquées « dup-oscSID » pour 0,1% de visites. On a donc supprimé le crawl vers ces pages pour récupérer globalement du crawl et on a amélioré le pagerank interne (pri sur le tableau) vers les fiches produits afin de diriger ce crawl récupéré vers ces pages stratégiques, efficaces et en plus nombreuses. Conséquence: le trafic a grimpé en flèche.
Efficacité du crawl de Googlebot
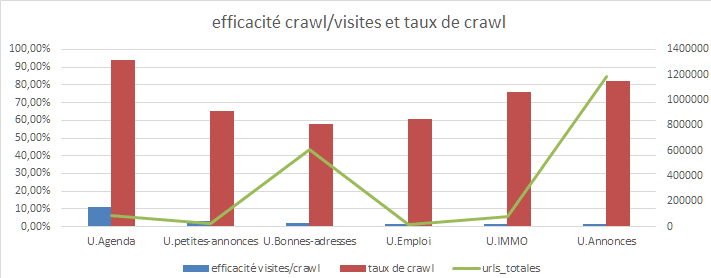
On peut calculer l’efficacité du crawl de Googlebot de différentes manières mais j’aime bien utiliser le ratio crawl / visites, soit la propension d’une page à générer des visites en fonction du temps passé par Google sur cette page. Si Google crawle peu souvent une page ou un groupe de pages, mais qu’elles génèrent beaucoup de visites, on peut considérer que le temps passé par Googlebot sur ces pages est particulièrement prolifique.
C’est encore plus intéressant lorsqu’on met en parallèle avec d’autres données comme:
- Taux de crawl: part des pages vues par Google sur celles dans la structure
- Urls totales: le volume d’urls au total dans la structure du site
- Le pagerank interne du site
- Des KPI sur le comportement utilisateur (temps passé, temps de chargement,…)
- …
Vous verrez le graphe ci-dessus dans aucun outil mais vous pouvez très bien le créer après export et traitement sur excel. Pourtant, ce simple graphe est riche d’informations. Les catégories de page sont classés par gros univers sémantiques et par ordre d’efficacité crawl / visites. On peut y voir par exemple que l’univers bonnes adresses est la 2 ème catégorie de pages avec le plus grand nombre d’urls derrière les annonces, c’est aussi la 3 ème catégorie de pages la plus efficace. Mais son taux de crawl est seulement de 58%, c’est à dire que Google ne voit que 58% des pages présentes sur le site. Ça signifie que si on augmente le taux de crawl de ces pages, on a un très gros potentiel de trafic., c’est mécanique.
Quelle période de logs analyser

Bon, j’ai regardé un peu d’autres sites avant d’écrire cet article pour voir comment il traitait le sujet et sur la question de la période de logs à analyser, c’est pas très précis pour rester soft. Ce que j’ai appris, de par mon expérience, c’est qu’il n’y a pas une période de logs valable pour tous les sites. Ça dépend de la fenêtre de crawl, soit le temps moyen nécessaire entre 2 passages de googlebot pour que le site génère 90% de ses visites. Cette fenêtre de crawl permet de déterminer la fréquence en dessous de laquelle une page a peu de chances de faire des visites. On peut parler aussi d ‘age des pages actives.
Vous me direz: « On peut pas le savoir avant d’avoir analyser les logs ! » Et vous avez raison, c’est pour ça que c’est bien de demander un peu plus de logs, analyser la fenêtre de crawl et ensuite réaliser la « vraie » analyse sur la période calculée. Le fait est qu’en général on est souvent sur une période oscillant entre 1 semaine et 3 semaines, ça dépend grandement de la typologie de trafic du site: majoritairement longue traîne ? moyenne traîne ? top traîne ? et aussi de la rotation des pages sur le site, l’apport de pages nouvelles.
Google crawle différemment les pages selon qu’elles sont plutôt porteuses d’expressions concurrentielles ou non, selon que les requêtes demandent ou non un contenu fréquemment mis à jour, etc.. Par exemple, sur une page plutôt porteuse d’expressions longue traîne comme un article sur un sujet de niche, Google ne va pas s’amuser à l’explorer 4 fois par jour car c’est un contenu qui à priori ne bougera pas trop et pas trop concurrentiel.
Je parle bien en moyenne sur le site, prenons l’exemple d’un forum qui par nature se positionne en majorité sur de la longue traîne, voir de l’ultra longue traîne, et bien la fenêtre de crawl et donc la période de logs à analyser sera autour de 3 mois. Ça signifie que Google passe en moyenne une fois tous les 3 mois sur une page et c’est suffisant pour qu’elle génère une visite.
Choisir la bonne période est essentiel car si on prend trop long par exemple, tous les chiffres de taux de crawl, de fréquence de crawl, de taux de pages actives et autres auront tendance à être trop élevés, difficiles à interpréter et faux d’une certaine manière.
Exemples d’utilisation
Les exemples d’utilisations des logs sont nombreux, leur analyse et leur interprétation permet par exemple de:
- Détecter que des pages stratégiques bien que fortement crawlées, sont peu visitées. Dans ce cas, il s’agit souvent d’un problème pertinence de ces pages et il faut améliorer leur contenu, leur titres, etc..
- Détecter que des pages stratégiques avec beaucoup de pagerank interne sont peu crawlées et peu visitées. Dans ce cas il peut s’agit aussi d’un problème de sémantique mais aussi d’une mauvaise expérience utilisateur.
- Détecter que Google passe plus de temps à crawler des produits expirés que les nouveaux produits. Dans ce cas, on peut procéder par étapes, redirections des anciens produits vers sa catégorie parente le premier mois, puis code 410 pour signifier à Google de ne plus recrawler cette page.
- Détecter beaucoup de crawl en code non-200. Dans ce cas, on identifie les différentes sources et on procède à du nettoyage avec les solutions adéquates selon les cas: rel canonical, noindex, disallow, obfuscation, suppression, code 410, etc…
- Détecter que le crawl des paginations est volumineux et peu efficace. Dans ce cas, on va mettre les paginations en noindex, follow et aussi s’atteler à créer une plus grande diversité dans la navigation.
- Estimer le budget de crawl du site et ainsi connaitre le volume de pages qu’on peut se permettre d’ajouter d’un coup à son catalogue produits.
- Identifier l’age des pages actives, est ce que sont les vieilles pages ou les nouvelles pages qui font des visites ? Important pour savoir quelles types de pages privilégier structurellement.
Les outils pour analyser les logs
Vous l’aurez compris, les outils je les utilise surtout pour extraire rapidement les données des logs, ensuite je les triture , les manipule, les mélangent avec d’autres informations pour les faire parler. Aussi, les logs deviennent un vrai outil d’aide à la décision lorsqu’ils sont au moins croisés avec les données d’un crawler, il faut donc utiliser ces 2 types d’outils.
Bon, voici quelques outils que vous pouvez utiliser pour les analyser et qui font aussi la partie crawl:
- Oncrawl: le crawler est payant mais l’analyseur de logs est open-source
- Botify: crawle et analyse de logs (cher)
- Screaming frog log file analyzer: Screaling frog , surtout connu pour son crawler, mais fait aussi analyseur de logs
Dans les outils qui font que de l’analyse de logs, il y en a un paquet mais voici une petite selection:
- ke.logs: Sympa!
- Ovh logs data platform: Pour du monitoring surtout et puissant si bien configuré.
- Seolyzer.io: Un petit nouveau que j’ai découvert il y a pas longtemps, prometteur !
Conclusion
Bon, j’espère que je vous ai pas trop perdu, je sais pas si ça se voit mais j’ai fais un gros effort de clareté. J’espère au moins vous avoir convaincu de l’intérêt de ce type d’analyses, aider à interpréter certaines données et vous avoir peut-être fait découvrir certaines faces cachées des logs.






Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !