Veille SEO du mois: Nouvel algo neural matching, nouveautés Google ,…

Ce qu’il ne fallait pas louper des nouveautés SEO et de Google ce mois-ci: Nouvel algorithme de correspondance neural, les nouveautés de Google annoncés pour ses 20 ans, nouveaux extrait enrichis, HTML et indexation, contenu caché sur mobile, …
20 ans de google : nouvelles fonctionnalités
Pour ses 20 ans Google a annoncé des nouveautés, largement basées sur l’intelligence artificielle, qui vont sortir dans les semaines et mois à venir:
- Résultats de recherche élargis « snippets » jusqu’à l’anticipation des requêtes en se basant sur ce qu’il sait de l’utilisateur
- Possibilité de Publier des stories, format alliant texte, photos et vidéos éphémères, comme sur les réseaux sociaux (ex: instragram)
- Pouvoir continuer ses recherches sur plusieurs jours en mettant de côté plus aisément les sites déjà visités
- Il va renforcer la recherche des images en permettant d’identifier un objet pris en photo.
- Google Feed devient Discover: L’écran d’accueil de Google sur Android qui donne des infos personnalisées sera dispo aussi sur le web et en bilingue pour ceux qui veulent
Nouvel Algorithme d’intelligence artificielle: La correspondance neurale
A l’occasion des 20 ans de Google Danny Sullivan a lancé une très grosse annonce sur l’existence d’un nouvel algorithme appelé Neural Matching ou “correspondance neurale” et qui impacterait déja 30% des requêtes.
Dans un tweet, Danny Sullivan parle d’une méthode pour mieux connecter les mots aux concepts. Pour l’illustrer, Voici une capture issue de la conférence de presse pour les 20 ans de Google:
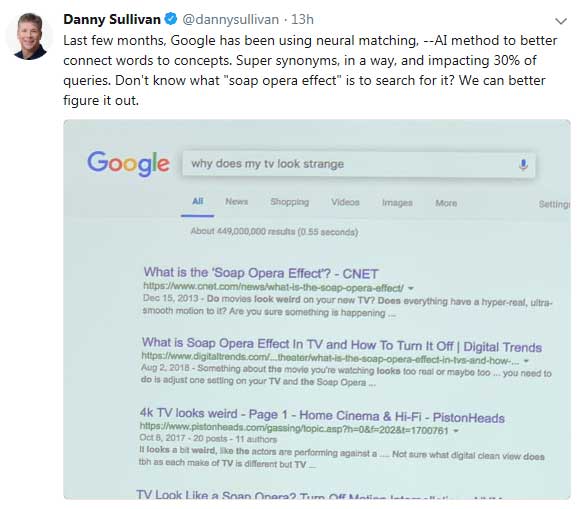
Danny Sullivan qui parle de la correspondance neurale et preuve par l’exemple
On voit que les résultats ne contiennent pas les mots clés de la recherche. Google tente de comprendre ce que l’utilisateur est en train de chercher.
Dans un autre tweet, il dit aussi que la façon dont les gens recherchent est souvent différente de la manière dont les gens répondent et l’illustre comme ceci:
This is a look back at a big change in search but which continues to be important: understanding synonyms. How people search is often different from information that people write solutions about. pic.twitter.com/sBcR4tR4eT
— Danny Sullivan (@dannysullivan) September 24, 2018
On voit que le même mot « change » prend différentes significations selon le contexte et Google le comprend. L’algorithme de correspondance neurale se base uniquement sur la correspondance entre la requête et la page, sans recours à des signaux traditionnels comme les liens. Le brevet de l’algorithme indique qu’il agit en fait après l’algorithme traditionnel en réordonnant les résultats.
Toute cela indique que la rédaction des contenus doit se focaliser sur l’intention de recherche des internautes et inclure un vocabulaire riche avec des mots du même champ sémantique comme des synonymes mais pas que. L’objectif étant notamment de faire en sorte que Google puisse bien attacher le sujet d’une page à son concept sémantique.
Les nouveaux extraits enrichis de Google

Récemment, Google a lancé de nouveaux featured snippets (extrait enrichis), qui à partir d’une recherche suffisamment large, vous déroule plus d’informations sous la forme de réponses directes. Sur l’exemple ci-dessus, on voit bien le snippet principal qui donne une définition de « emergency fund » et en dessous, des panneaux déroulants qui découpent le sujet recherché en sous-rubriques.
Au delà de cette mise à jour, ca donne des idées sur la manière dont Google perçoit un sujet et sur comment bien structurer les contenus d’un article par exemple.
Ces liens peuvent éventuellement renvoyer vers votre site, si votre contenu est assez clair et explicite pour répondre à ce découpage
L’HTML pour indexer son contenu plus rapidement
Yeah, there's no fixed timeframe — the rendering can happen fairly quickly in some cases, but usually it's on the order of days to a few weeks even. If your site produces new / updated content frequently & you want it indexed quickly, you need that content in the HTML.
— ? John ? (@JohnMu) September 13, 2018
John Muller de Google, en réponse à une question, affirme que Google crawl en 2 passes. Une première passe où Google explore uniquement le HTML et une deuxième passe où Google crawle la page entière et notamment le javascript. Entre ces 2 passes, il peut se passer quelques jours ou quelques semaines.
Il est donc important que Google puisse voir le contenu le plus important dès la première passe. Et pour être sur que son contenu soit indéxé rapidement et entièrement indéxé, il faut donc privilégier le HTML. Je vous recommande cet article pour plus d’infos sur le crawl Googlebot du javascript.
Les pénalités manuelles expirent avec le temps
Yes, manual actions expire after time. Often things change over the years, so what might have required manual intervention to solve / improve back then, might be handled better algorithmically nowadays.
— ? John ? (@JohnMu) September 7, 2018
Les pénalités manuelles, décidés par des actions humaines, expirent dans le temps et sont remplacés par des pénalités algorithmiques,. Par exemple, si un site a été pénalisé manuellement pour cause de mauvais liens, le filtre Google Penguin intégré au coeur de l’algorithme de Google, peut prendre le relais et adresser la pénalité automatiquement. Ca veux dire aussi que des pénalités manuelles peuvent être levées avec le temps sans qu’aucun algorithme prenne la relève.
La nouvelle search console sort de sa béta
La nouvelle search console devient la version par défaut. On y retrouve des versions remaniées des anciens rapports, quelques nouveautés mais il manque encore des rapports comme les statistiques d’exploration, l’outil de test du robots.txt, l’outil de changement d’adresse et beaucoup d’autres. Je pense qu’ils auraient pu rester en béta et pour l’instant l’ancienne search console reste accessible heureusement.
Contenu caché sur mobile
Selon ce qu’a déclaré Google à de nombreuses reprises, et notamment dans cette vidéo, au sujet de l’index mobile first:
- les contenus cachés (onglets, accordéons,.) sont acceptables, ils sont traités comme du contenu normal
- ils se classent tout aussi bien que le contenu visible directement
En effet, sur l’ancien index « desktop » le contenu caché pouvait être ignoré, mais visiblement ça devrait pas être le cas avec le nouvel index mobile first
Mais selon une étude de dejan marketing, les contenus cachés sur mobile first restent dévalués et ils préconisent de les éviter. Cette étude parait un peu bancale et sont en attente d’autres tests pour confirmer leur dires. Mon avis perso est qu’il faut continuer à mettre les contenus les plus importants visibles directement, ne serait ce que pour l’éxpérience utilisateur et d’utiliser les systèmes d’onglets avec parcimonie.






Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !